[境界要素法プログラムを設計する(基本のGauss掃き出し法)] [ネコ騙し数学]
[境界要素法プログラムを設計する(基本のGauss掃き出し法)]
1.Gauss掃き出し法の標準構成
前回の[外部手続き]の最後に、
REM Gauss掃き出し法 **********************************************
External Sub Gauss_0(A, z, n, Zero_Order, Return_Code)
REM まだ何にもしない
End Sub
という、よくわからんものがくっついてたはずです(^^)。今回はこの中身をつくろうという話です。Gauss掃き出し法は連立一次方程式を解く、標準解法です。なので別に境界要素法でなくても良いのですが(^^;)。
Gauss_0の引数Aは、解くべき連立一次方程式の係数マトリックスを表す配列,zはGauss_0が呼ばれた時は連立一次方程式の既知ベクトル(配列)で、Gauss_0の処理が終わると解ベクトルになっています。nは未知数の数,Zero_Orderは後述するピボット選択で使用する0判定オーダーを表す整数,Return_Codeは計算終了状態をGauss_0の外部へ伝えるために用意した引数です。
標準解法なので、数値計算業界(?)の業界標準みたいな構成があります。こういう構成です。
External Sub Gauss_0(A, z, n, Zero_Order, Return_Code)
External Sub Scaling
External Sub Foward_Eliminate
External Sub Back_Sub
REM スケーリング
Call Scaling(A, z, n, Return_Code)
If Return_Code <> 0 Then
Return
End If
REM 前進消去
Call Foward_Eliminate(A, z, n, Zero_Order, Return_Code)
If Return_Code <> 0 Then
Return
End If
REM 後退代入
Call Back_Sub(A, z, n)
End Sub
とりあえず、If Return_Code <> 0 ThenのIfブロックはおいといて、REM文の後のサブルーティン呼び出しに注目です。呼ばれるサブルーティンは、スケーリング(Scaling),前進消去(Foward Elimination),後退代入(Back Substitution)を行います。このうち前進消去と後退代入の意味がわからない人は、
ネコ先生の記事を読もう!。
2.スケーリング
スケーリングは桁落ち誤差対策です。連立一次方程式の係数マトリックスを表す配列Aは、ふつう倍精度浮動小数点実数で宣言されますが、倍精度浮動小数点実数型の公称有効数字は16桁と決まっています(国際規格)。以下は極端な例ですが、次の2元連立一次方程式を考えます。
![]()
上記を解くと、(2)-(1)で、
![]()
(2')より、
![]()
なので、(3)を(1)に代入し、
![]()
となります。(3),(4)より厳密解は、ほとんどx=2,y=1である事がわかります。数値計算には必ず数値誤差が憑きもの(?(^^;))です。なので例え数値誤差が憑いたとしても、x=2,y=1程度の近似解は出るようにしたい訳です。
同じ事をコンピューターにやらせると、既に(2')の段階でコンピューター内部では-(1+1020) → -1020,1-1020 → -1020という現象が起きてしまいます。有効数字が16桁しかないからです。
すると(3)でy=1となり、それを(1)に代入するとx=0となって全くお話になりません。何故ならx=0,y=1を(2)に代入すると、誤差がありとしても想定外の、-1=1という不当過ぎるな結果になるからです。
一方、
![]()
としてもOKなはずです。(1')は(1)の両辺を1020で割っただけのもの。ここで(2)-(1')をやるために、(1')のxの係数を1にしようとして、(1')を1020倍したら馬鹿です。(1)と(2)の状態に戻るので。(1')-10-20×(2)を試してみましょう。下から上を引いた方が考えやすいので行交換を行い、
![]()
として(1')-10-20×(2)を行うと、
![]()
(1")より、
![]()
と(3)と同じものが得られますが、これを(2)に代入すれば、x=2が得られます。
だまされたような気持ちですか?(^^)。でもこのトリックは正しいんです。理由はなんでしょう?。連立方程式の「構造」に注目します。(1)と(1')を比べると、条件(1')ではxの寄与は非常に小さいとわかります。無視してもいいくらいです。無視するとy=1です。それを(2)に代入しx=2。(1)と(1')は同じ条件のはずなのに・・・。
以上を強引にまとめると、こうなります。
大きすぎる数値で桁落ちが起こるより、非常に小さい数値で桁落ちが起こった方がましだ!。
そして桁落ちは必ず起こる!。
理由は連立方程式の中で微小な係数しか持たない部分は、最初から無視しても構造的に被害小だからです。いいかえれば、ちゃんとした近似構造を解いた。
しかし連立方程式の各条件は、何倍しても理屈の上では同じ条件。本当は寄与が少ない部分も、生の数値ではそう見えないかも知れない。よって寄与が少ないと見分けるためには、連立方程式の各行の数値桁数を揃えればいい、という話になります。そのために、連立方程式の各行を各行の絶対値最大成分の値で割り、各行の最大係数を1に揃える作業を、スケーリングと言います(← 一種のスケール規模問題です)。
スケーリングを行うと、連立方程式の数値的安定性は格段に向上します。でも数値誤差は憑き物(^^;)。弊害もあります。ほとんど特異な連立方程式(解けちゃいけない)が、安定に解けてとんでもない答えが出る場合もあります。そして人間は馬鹿だから、その答えを信じます(^^;)。
ところで(1')(2)を(2)(1')にしたような行交換を、機械は自動で出来るものでしょうか?。それは次のピボット選択と関連します。
ところで桁落ち誤差の意味がわからない人は、ネコ先生の記事を読もう!。
3.ピボット選択
ピボット選択は基本的に丸め誤差対策です。掃き出し中の連立一次方程式の係数配列は、概ね下図のようになります。灰色の部分は掃き出し完了ブロックで、成分は全て0です。Active行,Active列に囲われた部分が、これからs回目の掃き出しを行おうという、未処理ブロックになります。Active行,Active列の交点を、特にピボット(Pivot:枢軸)と言います。
掃き出し処理は、Active列のs+1行~n行成分を0にすれば完了です。そのためにまず、Active行をピボットassで割り、被処理行の頭の値as+2 sなどをActive行にかけて、非処理行から引きます。「/」を使う時には、常に割る数が0でないかどうかのチェックが必要です。
assがたまたま0という事はあり得ます。でもActive列の中には非零成分がたぶんあります。そこでActive列のs行~n行を検索し、最初に見つかった0でないaksを持つ行をActive行(s行)と交換し、k行目をActive行とすればOKです。もしActive列に非零成分がなければ、特異行列です。答えがでちゃいけません。そこで処理を中止します。
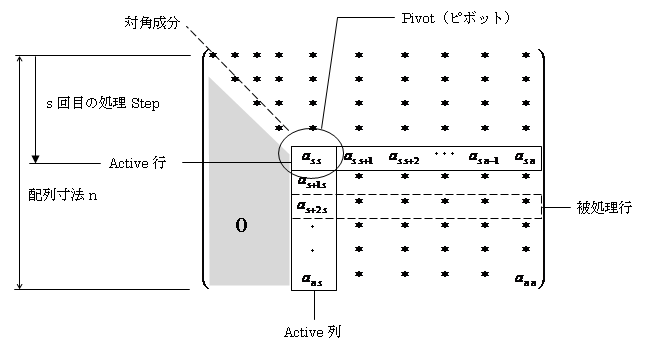
でも数値誤差は憑き物。本当は0なんだけど0に近いが0になってない数値はきっと、Active列にもごろごろしてます(^^;)。どれくらい小さければ0とみなすか?。要するに閾値Epsはどれくらいか?。これは問題のスケール規模で決まります。
係数配列の数値は平均的に非常に大きい場合もあるし、逆もありえます。両方で同じEpsを使っては計算精度なんか保証されません。でもスケーリングしたのでした。各行の最大成分は初期状態で必ず1です。スケール規模は「1」です。「1」を基準にEpsを決定できます(^^)。ここで引数Zero_Order登場です。Active列の非零成分検索で、絶対値が Eps=1.0 * 10^(-Zero_Order) 未満のものは0とみなします。自分は経験的にZero_Order=8を使います。
でも非零という条件だけでいいのでしょうか?。係数配列は初期状態においてすら、すでに各数値には丸め誤差δが含まれます。コンピューターの数値には、有限の有効桁数しかないからです。コンピューターの中の方程式とは、要するに最初から近似方程式なんですよ。数値誤差は数値計算の憑き物!(^^;)。
真の値がaij+δならば、それをピボットassで割る事により、丸め誤差の影響はδ/assになります。小さすぎるassで割ると、丸め誤差の影響は拡大します。もう一つ困るのはassが微小だと、スケーリングのところでやった(1')を、わざわざ(1)に戻すような事まで起きる可能性がある事です。せっかくスケーリングしたのに。
なので、Active列の絶対値最大成分を持つ行をActive行と交換します。これがピボット選択(行ピボット選択)です。あれっ、(1')と(2)の行交換が自動で出来ちゃった・・・(^^)。
スケーリングとピボット選択をセットで使うと、概ね6桁くらいの有効数字を数値誤差の影響から救えます。10^6=1,000,000なので、馬鹿にならない数字です。
ところで丸め誤差の意味がわからない人は、ネコ先生の記事を読もう!。
REM スケーリング
External Sub Scaling(A, z, n, Return_Code)
For i = 1 to n
Ma = 0
jj = 0
REM 行の絶対値最大成分を検索
For j = 1 to n
h = Abs(A(i, j))
If Ma < h Then
Ma = h
jj = j
End If
Next j
REM 行が0だったら処理中止
If Ma = 0 Then
Return_Code = 1
Return
End if
REM 絶対値最大成分で行を割り規格化
h = A(i, jj)
z(i) = z(i) / h
For j = 1 to n
A(i, j) = A(i, j) / h
Next j
Next i
Return_Code = 0
End Sub
REM 前進消去
External Sub Foward_Eliminate(A, z, n, Zero_Order, Return_Code)
REM 0判定値セット
Eps = 10^(- Zero_Order)
For i = 1 to n
REM Pivot検索
Ma = 0
ii = i
For k = i to n
h = Abs(A(k, i))
If Ma < h Then
Ma = h
ii = k
End If
Next k
REM Pivot候補がEps未満だったら処理中止
If Ma < Eps Then
Return_Code = 2
Return
End if
REM 行選択Pivot
If ii <> i Then
P1 = z(i)
P2 = z(ii)
z(i) = P2
z(ii) = P1
For j = i to n
P1 = A(i, j)
P2 = A(ii, j)
A(i, j) = P2
A(ii, j) = P1
Next j
REM 掃き出し処理
h = A(i, i) REM Pivotセット
z(i) = z(i) / h REM 既知ベクトルのActive行を規格化
For j = i + 1 to n REM 係数配列のActive行を規格化
A(i, j) = A(i, j) / h
Next j
For k = i + 1 to n REM 掃き出し
h = A(k, i) REM 非処理行の頭をセット
If h <> 0 Then REM Fillin Skip
z(k) = z(k) - h * z(i) REM 既知ベクトルの掃き出し
For j = i + 1 to n REM 係数配列の被処理行を掃き出し
A(k, j) = A(k, j) - h * A(i, j)
Next j
End If
Next k
Next i
Return_Code = 0
End Sub
REM 後退代入
External Sub Back_Sub(A, z, n)
For i = n to 1 Skip -1
h = 0
For j = n to i + 1 Skip -1
h = h - A(i, j) * z(j)
Next j
z(i) = h
Next i
End Sub
(執筆 ddt²さん)
極方程式で与えられた曲線に囲まれた部分の面積 [ネコ騙し数学]
極方程式で与えられた曲線に囲まれた部分の面積
曲線が極座標r、θを用いて
![]()
で表されているとき、この方程式を曲線Cの極方程式という。
5E22By5E23Da5E2-ebb63.png) 例えば、半径a(a>0)で点(a,0)を中心とする円
例えば、半径a(a>0)で点(a,0)を中心とする円
![]()
は、
![]()
と、極方程式で表すことができる。
また、デカルト直交座標における動点Pの座標を(x,y)とすると、

であり、
![]()
という関係がある。
定理
曲線Cが![]() で表されていて、f(θ)が連続であるとする。このとき、曲線Cと半直線θ=α、θ=βで囲まれた部分の面積は
で表されていて、f(θ)が連続であるとする。このとき、曲線Cと半直線θ=α、θ=βで囲まれた部分の面積は
![]()
である。
【略証】
![]()
(証明終)
 問題1 次の曲線(カージオイド)に囲まれている部分の面積を求めよ。
問題1 次の曲線(カージオイド)に囲まれている部分の面積を求めよ。
![]()
【解】
この曲線はx軸に関して対称なので、上半分の面積S₁を求め、それを2倍すればよい(右図参照)。
したがって、

したがって、この曲線によって囲まれる面積Sは
![]()
(解答終)
 問題2 次の曲線(レムニスケート)に囲まれている部分の面積を求めよ。
問題2 次の曲線(レムニスケート)に囲まれている部分の面積を求めよ。
![]()
【解】
この曲線はx軸、y軸に関して対称。だから、第1象限の面積を4倍すればよい。
![]()
とおくと、
![]()
は、

rが恒等的に0のときは曲線ではなく、原点になるので、
![]()
第1象限だけを考えればよいので、このとき、0≦θ≦π/2であり、また、(2)を満たさなければならないので、

よって、

したがって、
![]()
(解答終)
 問題3 次の曲線(3葉線)に囲まれる部分の面積を求めよ。
問題3 次の曲線(3葉線)に囲まれる部分の面積を求めよ。
![]()
【解】
![]()
とおくと、
![]()
求める面積は、第1象限でこの曲線によって囲まれる部分の面積S₁を3倍したもの。
ところで、0≦θ≦π/2で
![]()
になるのは、
![]()
したがって、
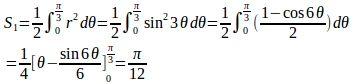
よって、
![]()
(解答終)
テーラー級数、マクローリン級数を使って [ネコ騙し数学]
テーラー級数、マクローリン級数を使って
まずは、テーラー級数を用いる次の問題を。
問題1
![]()
をx=1のまわりのテーラー級数に展開せよ。
これを利用して、log1.1を小数3桁まで正確に求めよ。
【解】

したがって、テーラー級数は
![]()
または、剰余項![]() を用いて
を用いて

log1.1を小数点以下3桁まで求めるには剰余項を
![]()
にすればよいので

したがって、n=3にとればよい。
よって、
![]()
で、誤差は
![]()
(解答終)
電卓で自然対数log1.1を求めると
![]()
したがって、小数点以下3桁まで正確に求められており、誤差の評価も概ね正しいことがわかる。
問題2 マクローリン展開の最初の4項を用いて次の微分方程式
![]()
の近似値を求めよ。
【解】
![]()
の両辺を順次xで微分すると、

したがって、

よって、
![]()
(解答終)
問題3 次の微分方程式を解け。
![]()
【解】
 この微分方程式はn=2のベルヌーイ形の微分方程式。
この微分方程式はn=2のベルヌーイ形の微分方程式。
だから、

とおくと、
![]()
よって、

(解答終)
グラフを見ると、問題2で求めた近似解は、−0.5≦x≦0.5の範囲で厳密解とよく一致していることがわかる。
なお、
差分法の基礎 [ネコ騙し数学]
差分法の基礎
f(x)を何回でも微分可能な関数とすると、テーラーの定理より、f(x)はx=aの近傍で
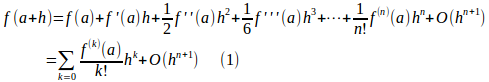
と展開することが可能である。
ここで、記号Oはランダウの(ビッグ)Oで
![]()
ある。
したがって、n=1,2,3とすると、
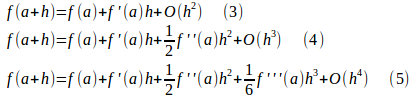
が成り立つ。
また、hを−hに置き換え、
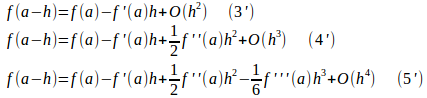
を得ることができる。
(3)式より、h≠0のとき、

となり、このことからf'(a)を
![]()
と近似したときの誤差はhのオーダー、![]() であると予想できる。
であると予想できる。
このことは、拡張された平均値の定理
![]()
より、h≠0のとき、
![]()
となり、f''(x)は
![]()
で連続だから
![]()
となるMが存在し、
![]()
となり、
![]()
と近似した誤差が|h|のオーダー程度であることが確かめられる。
 f(x)がxの1次関数の時、
f(x)がxの1次関数の時、
![]()
なので、
![]()
が成立すので、(6)は1次の精度である。
![]() さらにa=0とし、hを変化させ、
さらにa=0とし、hを変化させ、
と近似したときの誤差を求めてみると、右の図のようになる。
横軸にはh、縦軸に誤差をとり、対数グラフで結果を表している。
この直選の傾きが1であることから、(6)の近似式の誤差がhの1次オーダーであることが確かめられる。
このことを、
![]()
と表すことにする。また、f'(a)のこの近似式を前進差分と呼ぶことにする。
また、f'(a)を求めるために、(3)と(3’)の辺々を引くと、

が得られる。
 (8)式で与えられるf'(a)の近似式を中心差分と呼び、この近似式の誤差はhの2次のオーダーであることと予想できる。
(8)式で与えられるf'(a)の近似式を中心差分と呼び、この近似式の誤差はhの2次のオーダーであることと予想できる。
![]() さらにa=0とし、hを変化させ、
さらにa=0とし、hを変化させ、
![]()
と近似したときの誤差を求めると右図のようになる。このときの直線(緑色の直線)の勾配は2であり、この近似式の誤差はhの2次オーダーであることがわかる。
f(x)がxの2次関数であるとき、
![]()
となるので、
![]()
が成立する。したがって、この近似式は2次の精度を持っている。
要するに、![]() という記号は、n次の精度で、誤差の程度は
という記号は、n次の精度で、誤差の程度は![]() のオーダーであり、hを1/10にすると、誤差は
のオーダーであり、hを1/10にすると、誤差は![]() になるということを表していると考えることができる。
になるということを表していると考えることができる。
![]() の近似式を求めるために、(5)と(5’)の辺々を加えると、
の近似式を求めるために、(5)と(5’)の辺々を加えると、
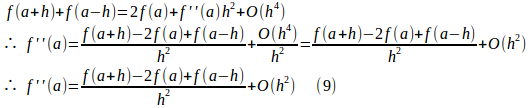
 したがって、
したがって、
![]()
という近似式は、2次の精度をもっており、誤差はh²程度ということになる。
この直線の傾きは2であり、誤差がhの2次のオーダーであることが確かめられる。



